
Methode
Gebruikte data
De resultaten in dit hoofdstuk zijn gebaseerd op de beschikbare gegevens van 6.296 Utrechtse volwassenen (18 t/m 64 jaar) die in het najaar van 2020 de vragenlijst van de Gezondheidsmonitor Volwassenen hebben ingevuld.
Samenstelling gezondheidsgroepen
De gezondheidsgroepen zijn vastgesteld door middel van een latente klasse analyse op de gegevens over de gezondheidskenmerken. Hiervoor is gebruikgemaakt van het R-package ‘VarSelLCM’. Een oplossing met acht of negen groepen was statistisch gezien even goed. Op inhoudelijke gronden is gekozen voor een oplossing met negen groepen. De oplossing met negen groepen geeft een duidelijk onderscheid tussen de ‘goed gezonde’ groep en de ‘gezond, met (risico op) overgewicht’-groep. In de oplossing met acht groepen vormen deze twee groepen samen één groep. Verschillen tussen groepen in gezondheidskenmerken zijn getoetst met een chi-kwadraat-toets.
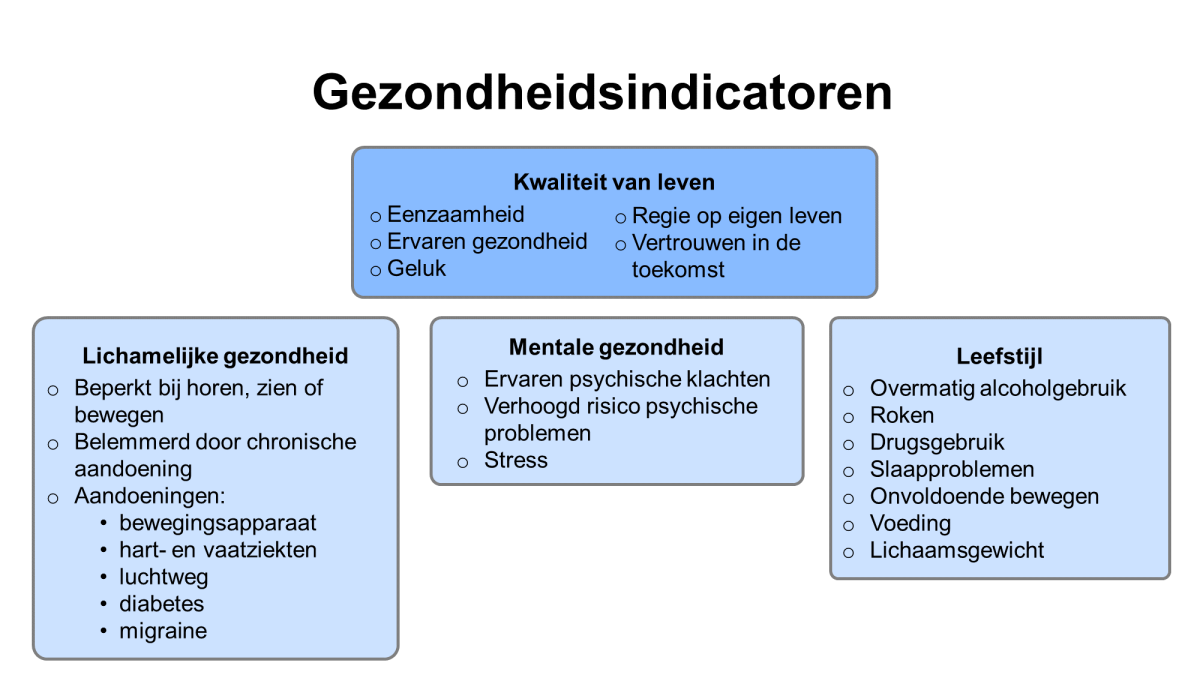
Figuur 40. Gezondheidskenmerken die in het onderzoek zijn meegenomen
Samenhang met factoren die gezondheid beïnvloeden
Verschillen tussen groepen in factoren die gezondheid beïnvloeden, zijn getoetst met een chi-kwadraat toets. Door middel van extreme gradient boosting in het R-package ‘XGBoost’ is vastgesteld of en op basis van welke beïnvloedende factoren een onderscheid gemaakt kan worden tussen volwassenen die zich zeer gezond voelen en volwassenen met een ander gezondheidspatroon. Dit was alleen mogelijk voor de drie groepen die zich ongezond voelen. De factoren die gezondheid beïnvloeden verschillen bij Utrechters die zich zeer gezond voelen niet wezenlijk van die van Utrechters in andere groepen die zich gezond voelen.
Figuur 41. Factoren die gezondheid beïnvloeden die in het onderzoek zijn meegenomen
